Building an RNN From Scratch for Text Synthesis
Recurrent Neural Network (RNN) Implementation in Python for Text Synthesis
Introduction
In this project, I implemented a vanilla recurrent neural network from scratch and trained it on text from a Harry Potter book character-by-character using the back-propagation through time (BPTT) algorithm. The trained network was then used to generate text one character at a time.
Demo
Generate some text from my trained model by pressing the blue button in the box below:
Implementation
The source code can be found on my github repo here. Feel free to try it out :).
Recurrent neural networks (RNNs) are designed to maintain a record of past outputs as input for the current prediction. This is usually accomplished through their hidden states and self-connections between nodes. My implementation of the vanilla RNN includes a single layer where prior outputs are incorporated into the current output calculation. The softmax activation function is used for the output, allowing for comparison to the one-hot encoded character data. The model's default activation function is softmax. Figure 1 below depicts the model's computations.
To train the network weights, I minimized the cross-entropy loss using the BPTT algorithm to compute gradients. In my implementation, I used AdaGrad (adaptive gradient), a variant of stochastic gradient descent, to adjust the weights. AdaGrad is useful in natural language applications because it adapts the learning rate based on the frequency of different data points, in our case, the characters.
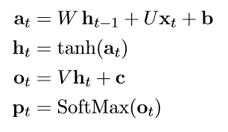
To validate the correctness of my BPTT implementation, I conducted a comparison of the five analytically computed gradients with numerically computed gradients. The comparison employed relative error, defined as follows:
\( relative\_error = \frac{\left | g_a - g_n \right |}{max\left (\epsilon, \left | g_a \right | + \left | g_n \right | \right )} \)
where ϵ = 1e-16, ga represents the analytically computed gradient, and gn represents the numerically computed gradient (computed using the centred difference formula with h=1e-4). A limited network with seq_length=25 and a hidden layer node count of 5 was tested for one forward/backward pass. The maximum relative errors for each layer, along with the average relative difference, are presented in Table 1. The maximum relative errors are approximately 2e-6 or less for each layer, which I consider sufficiently small for the purpose of this study. Based on these results, I am confident in the accuracy of the gradients.
| Weights | max | avg |
|---|---|---|
| b | 6.21e-09 | 3.45e-09 |
| c | 9.74e-10 | 7.07e-10 |
| U | 5.38e-08 | 7.64e-10 |
| W | 1.87e-06 | 1.92e-07 |
| V | 2.72e-07 | 1.58e-08 |
| All | 1.87e-06 |
During text generation, I introduced a slight modification to the probability distribution of the predicted next character. Specifically, I slightly increased the probabilities associated with high-probability characters to reduce noise when synthesizing text.
Dataset
The data set used for training was the entire book Harry Potter and the Goblet of Fire.
Results
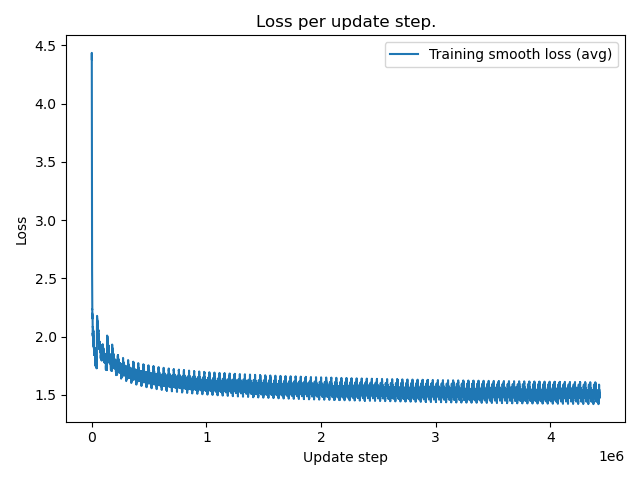
Upon training a network with 100 hidden nodes for 100 epochs, I generated text that closely resembles the style of the original book. An excerpt of the generated text is provided below. The smooth loss plot is presented in Figure 2. As expected, some of the generated words are not found in the original text, as vanilla RNNs have limited ability to remember long-term dependencies, resulting in fading information from previous time steps. In contrast, LSTM or GRU networks are more adept at preserving important temporal information, which would be evident in this application. An individual without proficiency in English would likely have difficulty distinguishing the synthesized text from the original text.
Example of text synthesis:
"But Hagrid, and with so only had about his agred and said to siven out on of them on the step the certher carried them enter. "See knows slidnars. Pount, and get that's him and his fire of Hermione which of of owe to started her now. "Don't table. "Oh Weasley morning to and someed it, chere. Moody had so slows; lookians was hore has as the egg siden into getter a of Madget the time was magicule from the luftis days fice her under reared." "Lo, and a didn't sazihm to disundinger that a mon looked me like the mourem. "When he looked a crow, and past with the hizg you they wasn't clotelber to go looking madiins was here to sure thing. They're for the flevecon slowly." "Wheer. CHal- firit are," said Moody, and spuy didn't sweremely didn't he saw Krum, and Dumbledores been and ready trying to the work, and down prosed like not and her say, smart more up place arry as Hermione standing reager to dran't were spon't out of the mistion year of the from the two was idea still and was ou