An NLP application on SOMs
Using Self-Organizing Maps to Represent Word Vectors on a 2D map while preserving the topology of the original input space
This project aims at representing some of the most common English words on a 2D topological map. It is done by using a self-organizing map (SOM), also known as a Kohonen neural network. These networks apply competitive learning to preserve the topology of the data points in higher dimensional feature space to lower-dimensional ones. This is useful for visualising high dimensional data. The github repo with all the code can be found here.
Experiments
In the experiments of this project, pre-trained word vectors were used as input vectors and a 2D uniform grid of varying size were used as output space. Lists of the most common words in different domains were found on the internet and are described further below for each experiment. Find out more about how the data files were formatted in the data directory in the github repository.
The English language
In the first experiment, pre-trained 300-dimensional glove word vectors (glove.6B.300d.txt) made available by Stanford University were used. The output space consisted of a 40x40 uniform grid. To determine the 2000 most commonly used words in the English language, the list google-10000-english-no-swears.txt from this repository was used. The words in this list were determined by n-gram frequency analysis of the Google's Trillion Word Corpus. These 2000 words were the words included in the input space during training and plotting. The units/vertices in the grid were labelled to the label that the closest data point has (Euclidean distance).
Training Parameters used:
| Parameter | value |
|---|---|
| Words | 2000 |
| Epochs | 500 |
| Learning rate | 0.2 |
| Unit initialisation | Gaussian(0,1) |
| Grid size | 40x40 |
| Initial neighborhood range | 40 (Manhattan distance) |
The resulting plot can be seen here:
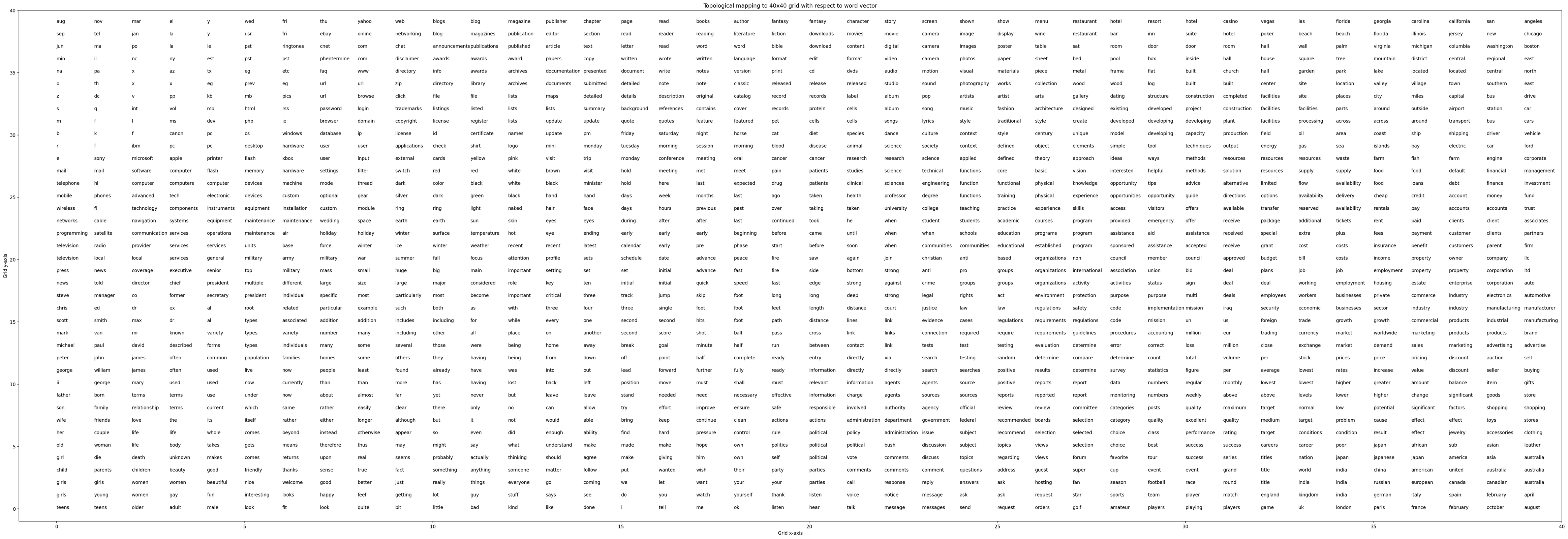
Click here to view the picture in a new tab.
As seen on the results, similar words are positioned close to each other.
The Swedish language
A similar experiment was done for the Swedish language as for the English language. The Swedish word vectors are 300-dimensional and are trained by Facebook Research. The word vectors can be found on their github repository and are licenced under the Creative Commons Attribution-Share-Alike License 3.0. The 600 most frequently used words in the Swedish language were included and the source I used to identify them can be found here. The units/vertices in the grid were labelled to the label that the closest data point has (Euclidean distance).
Training Parameters used:
| Parameter | value |
|---|---|
| Words | 600 |
| Epochs | 500 |
| Learning rate | 0.2 |
| Unit initialisation | Gaussian(0,1) |
| Grid size | 20x20 |
| Initial neighborhood range | 20 (Manhattan distance) |
The resulting plot can be seen here (hover to zoom):
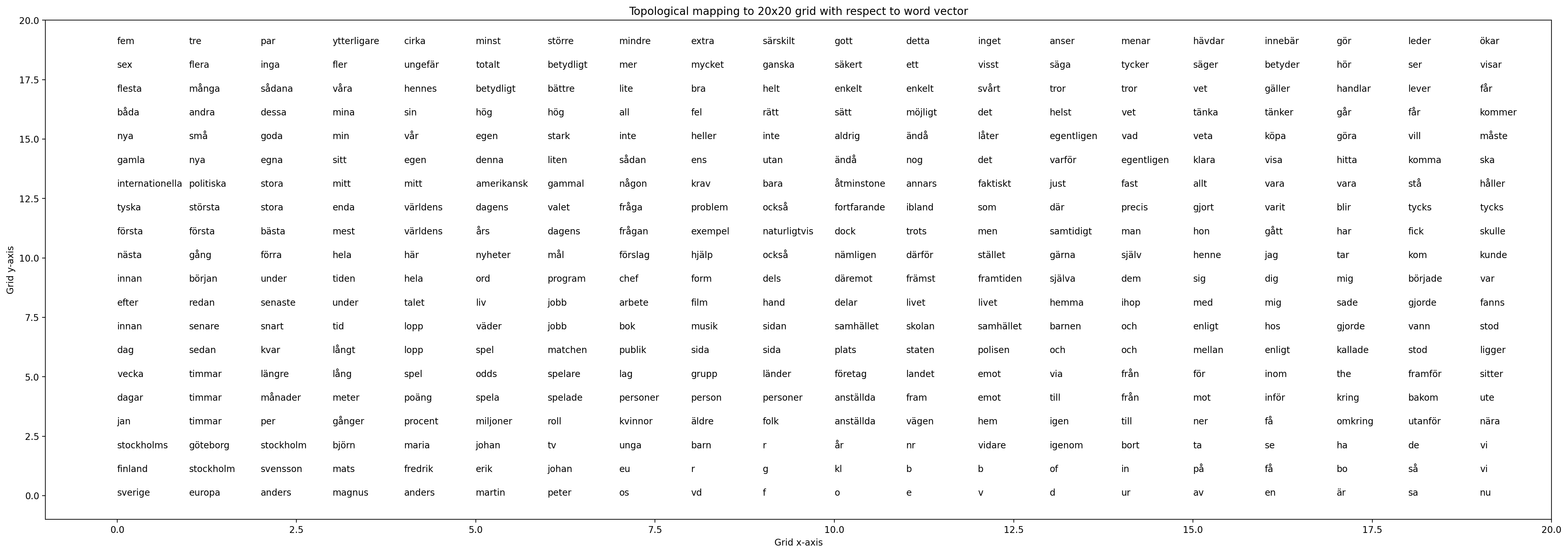
Click here to view the picture in a new tab.
As seen on the results, similar words are positioned close to each other.